Модели ИИ, играющие в игры обучение действиям по устным инструкциям
Модели искусственного интеллекта для игр существуют уже десятилетия, но обычно они сфокусированы на одной игре и всегда стремятся к победе. Исследователи Google Deepmind выбирают иной подход.
Google DeepMind обучает искусственный интеллект быть вашим напарником в видеоиграх!
Модели искусственного интеллекта, играющие в игры, существуют на протяжении десятилетий, но часто они ограничивались специализацией в одной игре и всегда стремились к победе. Однако исследователи Google DeepMind взяли другой путь с своим новейшим творением – моделью, которая не только учится играть в несколько 3D-игр, как человек, но и старается понимать и действовать по устным инструкциям.
В большинстве игр уже есть искусственный интеллект или компьютерные персонажи, которые могут выполнять аналогичные действия, но обычно они управляются косвенно через формальные игровые команды. Новая модель DeepMind, называемая SIMA (масштабируемый обучаемый агент для многомерного мира), отказывается от этого подхода. Вместо доступа к внутреннему коду или правилам игры, SIMA была обучена на бесчисленных часах видеоматериала, показывающего игровой процесс человеком. Модель учится ассоциировать конкретные визуальные представления действий, объектов и взаимодействий через этот материал, вместе с аннотациями, предоставленными специалистами по разметке данных. Исследователи также записывали видеоигры, в которых игроки инструктировали друг друга выполнять задания в игре.
Например, модель может усвоить, что определенный узор движения пикселей на экране соответствует действию “передвижение вперед”. Аналогично, когда персонаж подходит к объекту в виде двери и использует припоминающий ручку объект, модель распознает это как “открытие” “двери”. Это простые задачи или события, которые занимают несколько секунд, но требуют больше, чем простое нажатие кнопки или идентификация чего-то.
Видеозаписи обучения были взяты из различных игр, начиная с Valheim и заканчивая Goat Simulator 3. Разработчики этих игр были вовлечены и согласились на использование своего программного обеспечения. Одной из основных целей исследователей было определить, сделает ли обучение модели искусственного интеллекта для игры в один набор игр способной играть в другие, которые она никогда не видела ранее – процесс, известный как обобщение.
Ответ, с некоторыми оговорками, – да. Искусственные агенты, обученные на нескольких играх, справлялись лучше в играх, с которыми они не взаимодействовали прежде. Однако важно отметить, что многие игры включают специфическую механику или термины, которые могут составлять вызовы даже для самых подготовленных искусственных интеллектов. Тем не менее, модель может изучить эти тонкости при достаточном объеме обучающих данных.
- Volley Революция в ракеточных видах спорта благодаря машине для тре...
- Nintendo Switch Причины покупки и скидки, которые нельзя пропустить...
- Омни Уан Игра-переворотник в мире виртуальной реальности 🏃♂️
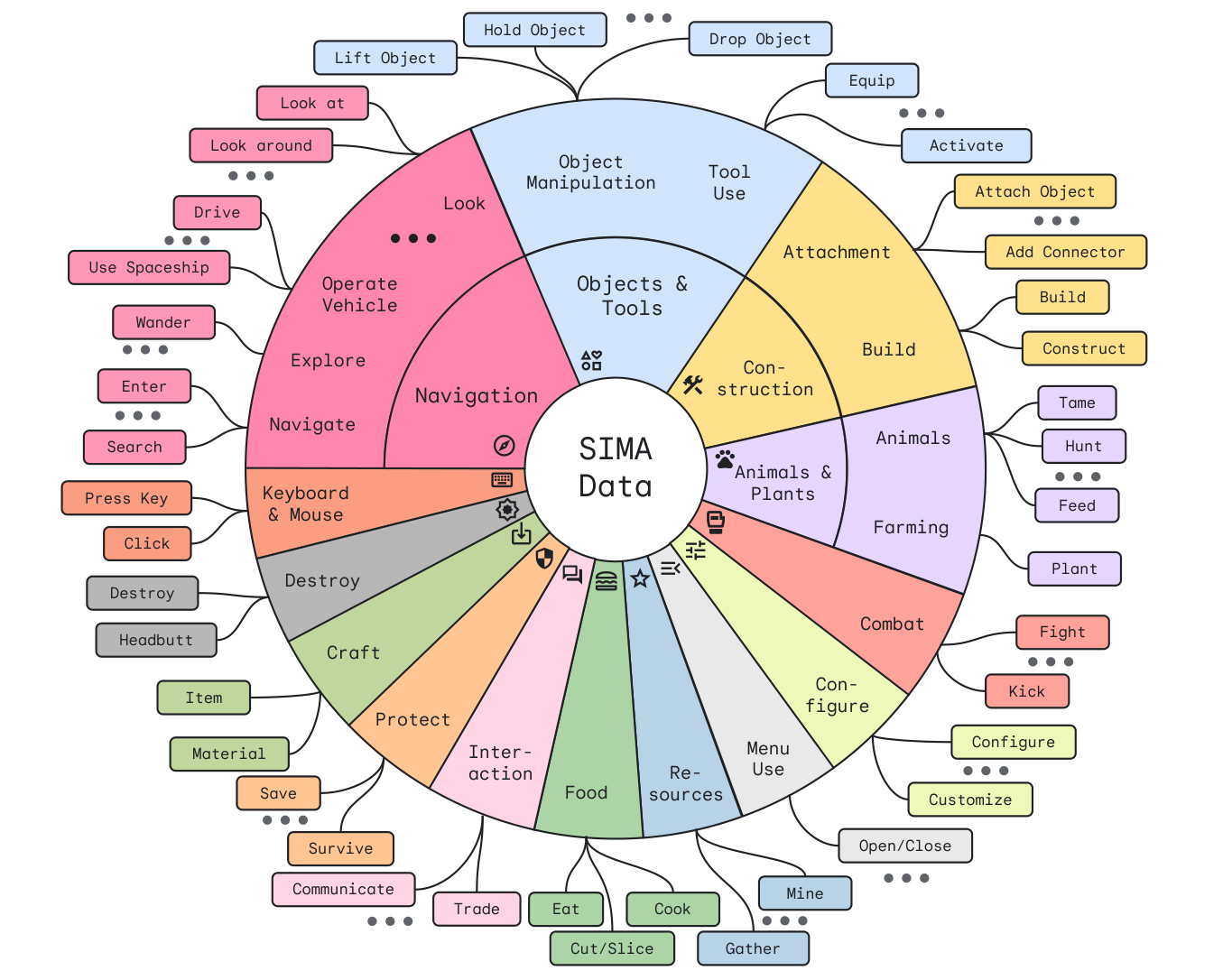
Интересно, несмотря на разнообразие игрового жаргона, существует лишь ограниченное количество “глаголов”, которыми обладают игроки и которые значительно влияют на игровой мир. Будь то сборка лаунджа, постановка палатки или призыв магического убежища, в конечном итоге вы “строите дом”. Эта карта иллюстрирует несколько десятков примитивов, которые агент SIMA в настоящее время узнает, показывая, как он интерпретирует различные действия в игре:
🏢 Строительство дома 🛡 Защита 🍌 Сбор ресурсов ✈ Путешествие
Амбициями исследователей, помимо продвижения искусственного интеллекта на основе агента, является создание более естественного компаньона по игре, чем жестко заложенные, стандартные агенты, которые у нас есть сегодня. Вместо сражения с супер-человеческим искусственным интеллектом игроки могли бы иметь рядом с собой игроки SIMA, которые являются кооперативными и отзывчивыми на устные инструкции. Поскольку игроки SIMA видят только пиксели игрового экрана, они учатся выполнять задачи подобно людям. Это позволяет им адаптироваться и развивать внезапные поведенческие модели.
🤖💬 Хотите узнать, как искусственный интеллект трансформирует различные отрасли? Ознакомьтесь с этим видео, чтобы увидеть больше реальных примеров применения искусственного интеллекта в действии: Открытое сотрудничество и создание 👈
Теперь вы, возможно, задаетесь вопросом, насколько этот подход сопоставим с методом симулятора, обычно используемым при создании агентов-агентов. В симуляторном подходе частично безнадзорная модель экспериментирует в 3D-моделированном мире, интуитивно уча правила и разрабатывая поведение на их основе. Однако этот метод требует сигнала вознаграждения, предоставленного игрой или окружающей средой, из которого агент может учиться. Во многих коммерческих играх такие сигналы недоступны. Более того, исследователи были заинтересованы в обучении агентов, способных выполнять широкий спектр задач, описанных в открытом тексте, что было бы непрактично оценить, используя конкретные сигналы награды для каждой цели. Вместо этого агентов обучали методом имитационного обучения по человеческому поведению, где цели предоставлялись в текстовом формате.
Этот подход позволяет агентам преследовать более широкий спектр целей, поскольку он не ограничивается строгой структурой наград. Вместо того чтобы быть направляемыми исключительно очками или результатами победы/поражения, агенты могут быть обучены ценить более абстрактные критерии, такие как сходство своих действий с предыдущими. Следовательно, их можно обучить “желать” выполнять практически любую задачу, при условии представления обучающих данных несколькими способами.
“`html
Подобные инициативы также изучаются другими компаниями. НПС в играх рассматриваются как потенциальные возможности для использования больших языковых моделей (LLM) в качестве чат-ботов. Кроме того, исследования в области ИИ занимаются моделированием и отслеживанием простых импровизированных действий или взаимодействий, что приводит к разработке увлекательного поведения агентов. Например, исследователям удалось успешно заселить крошечный виртуальный город ИИ, что привело к полезным взаимодействиям и ощущению сообщества.
🏡👥 Хотите узнать больше о виртуальном городе, населенном ИИ? Читайте об этом в этой статье: Исследователи заселили крошечный виртуальный город ИИ (и это было очень полезно)
Наконец, продолжаются эксперименты по изучению бесконечных игр, таких как MarioGPT, которые исследуют потенциал ИИ для игр с бесконечными возможностями. Однако это тема для другого обсуждения.
В заключение, модель SIMA DeepMind представляет собой значительное развитие в области игровых агентов ИИ. Обучая модели учиться на основе игр пользователей и реагировать на устные инструкции, исследователи не только расширяют границы ИИ, но и стремятся создать более естественных, сотрудничающих и интерактивных игровых спутников. По мере развития ИИ мы можем ожидать появления новых и увлекательных приложений в различных отраслях и формах развлечений.
Q&A
Q: Могут ли ИИ-модели, обученные на нескольких играх, эффективно играть в игры, которые им неизвестны?
О: Да, ИИ-агенты, обученные на нескольких играх, показали способность хорошо справляться с играми, с которыми они не имели опыта. Однако в отдельных играх могут возникнуть специфические механики или термины, которые могут представлять вызов для ИИ-моделей. При наличии достаточного объема обучающих данных модель может преодолеть эти трудности.
Q: Как модель SIMA учится понимать устные инструкции в играх?
О: Модель SIMA обучается на видеозаписях людей, играющих в игры, вместе с аннотациями, предоставленными операторами по разметке данных. Связывая визуальные представления действий, объектов и взаимодействий с устными инструкциями, модель учится понимать и действовать по этим инструкциям.
Q: В чем различие обучения модели SIMA от традиционного обучения агента на основе симулятора?
О: Традиционное обучение агента на основе симулятора основано на обучении с подкреплением и требует сигнала вознаграждения от игры или окружения. Однако подход обучения SIMA сосредоточен на имитационном обучении на основе поведения людей, используя открытые цели текста вместо конкретных сигналов вознаграждения. Это позволяет модели решать более широкий спектр задач и целей.
Q: Есть ли другие применения ИИ в играх помимо игр и понимания игр?
О: Конечно! У ИИ есть много применений в играх, включая поведение НПС, реалистичные физические симуляции, распознавание речи для управления в игре и многое другое. Технологии ИИ продолжают развиваться, улучшая различные аспекты игрового опыта.
📚 Ссылки: – AGent57 AI агент DeepMind может обыграть лучших игроков в 57 играх Atari – Исследователи заселили крошечный виртуальный город ИИ (и это было очень полезно) – Совместное сотрудничество и творчество (Видео)
Каковы ваши мысли о ИИ-моделях, способных играть в игры как люди и реагировать на устные инструкции? Считаете ли вы, что эта технология имеет потенциал изменить игровую индустрию? Поделитесь своими мнениями в комментариях ниже! И не забудьте поделиться этой статьей с друзьями в социальных сетях! 🎮🤖✨
“`