Как Google и UCLA подталкивают ИИ к выбору следующего действия для лучшего ответа
Google и UCLA развивают ИИ для лучшего выбора следующего действия
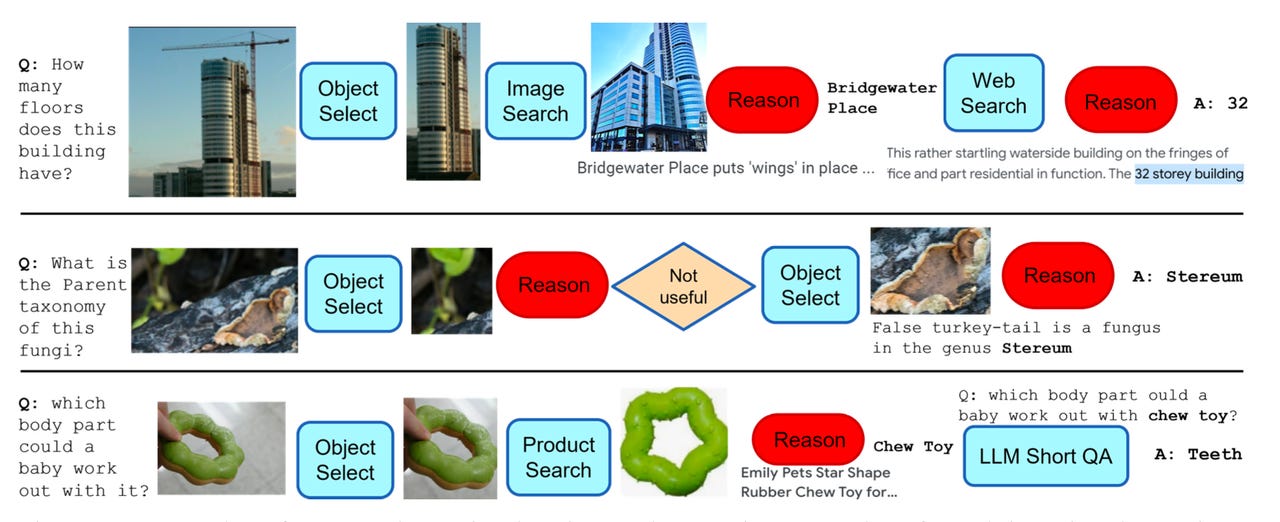
Программа AVIS от Google может динамически выбирать серию шагов для выполнения, таких как идентификация объекта на картинке, а затем поиск информации об этом объекте.
Программы искусственного интеллекта поражают публику своей способностью давать ответы на любые вопросы. Однако, качество ответов часто оставляет желать лучшего, поскольку программы, такие как ChatGPT, просто реагируют на текстовый ввод, не имея основания в предметной области, и могут производить откровенные неправды в результате.
Недавний исследовательский проект от Университета Калифорнии и Google позволяет большим языковым моделям, таким как Chat-GPT, выбирать конкретный инструмент – поиск веб-сайтов или оптическое распознавание символов, – который затем может искать ответы в несколько шагов из альтернативного источника.
Также: Исследователи заявляют, что ChatGPT лжет о научных результатах и требует альтернатив с открытым исходным кодом
Результатом является примитивная форма “планирования” и “рассуждения”, способ для программы определить, как подходить к вопросу в каждый момент и, после решения, было ли решение удовлетворительным.
- Глава фармацевтической компании Не прекращайте исследования в облас...
- «Эти новые среднебюджетные пылесосы Roborock могут заставить вас пе...
- Cerebras и Абу-Даби создают самую мощную в мире модель искусственно...
Разработка, названная AVIS (Autonomous Visual Information Seeking with Large Language Models) исследователями Ziniu Hu и коллегами из Университета Калифорнии в Лос-Анджелесе и соавторами из Google Research, размещена на сервере предварительных печатных материалов arXiv.
AVIS базируется на языковой модели Pathways Language Model (PaLM) от Google, которая породила несколько версий, адаптированных под различные подходы и эксперименты в генеративном искусственном интеллекте.
AVIS продолжает традиции недавних исследований, направленных на превращение программ машинного обучения в “агенты”, которые действуют более широко, чем просто предсказывание следующего слова. К ним относятся BabyAGI – “система управления задачами на базе искусственного интеллекта”, представленная в этом году, и PaLM*E, также представленная в этом году исследователями Google, которая может указывать роботу следовать серии действий в физическом пространстве.
Величайшим прорывом программы AVIS является то, что, в отличие от BabyAGI и PaLM*E, она не следует заранее заданному плану действий. Вместо этого она использует алгоритм, называемый “Планировщик”, который выбирает между набором возможных действий на лету, по мере возникновения каждой ситуации. Эти выборы генерируются в процессе оценки языковой моделью предложенного текста, разбивая его на подвопросы и затем связывая эти подвопросы с набором возможных действий.
Даже выбор действий представляет собой новый подход здесь.
Также: Google обновляет Vector AI для обучения GenAI на собственных данных предприятий
Ху и его коллеги провели опрос 10 человек, которым нужно было ответить на одинаковые типы вопросов – такие как “Как называется насекомое?” показано на картинке. Их выборы инструментов, таких как поиск изображений Google, были записаны.
Затем авторы поместили эти примеры выбора человека в то, что они называют “графом переходов”, моделью того, как люди делают выбор инструментов в каждый момент.
Затем Планировщик использует граф, выбирая из “подходящих контексту примеров […], которые формируются на основе решений, принятых ранее людьми.” Это способ заставить программу моделировать выборы людей, используя прошлые примеры как дополнительный вход для языковой модели.
Также: Многопросмотр AI приходит, и он будет мощным
Чтобы проверить свои выборы, программа AVIS имеет второй алгоритм, “Рассуждающий”, который оценивает полезность каждого инструмента после его использования языковой моделью, прежде чем решить, выдавать ли ответ на исходный вопрос. Если конкретный выбор инструмента не был полезным, Рассуждающий отправит Планировщик на переработку.
Общий рабочий процесс AVIS состоит в составлении вопросов, выборе инструментов и использовании Рассуждающего для проверки, дал ли инструмент удовлетворительный ответ.
Ху и его команда протестировали AVIS на некоторых стандартных автоматизированных бенчмарках для визуального вопросно-ответного тестирования, таких как OK-VQA, представленный в 2019 году исследователями Карнеги-Меллонского университета. По этому тесту AVIS достигла “точности 60,2, что выше, чем у большинства существующих методов, адаптированных для данного набора данных”, сообщают они. Другими словами, общий подход здесь превосходит методы, которые были тщательно адаптированы для определенной задачи, что является примером всеобщности машинного обучения и искусственного интеллекта.
Также: Генеративный ИИ занимает первое место в списке 25 ведущих новых технологий Gartner на 2023 год
В заключение Ху и команда отмечают, что они планируют двигаться дальше вопросов, связанных только с изображениями в будущих работах. “Мы стремимся расширить нашу динамическую рамку принятия решений, работающую на основе LLM, чтобы решать другие задачи логического вывода”, – пишут они.