Ученые Алекса от Amazon демонстрируют, что в большинстве случаев более крупный искусственный интеллект не всегда лучше.
Ученые Алекса от Amazon показывают, что больше ИИ не всегда лучше.
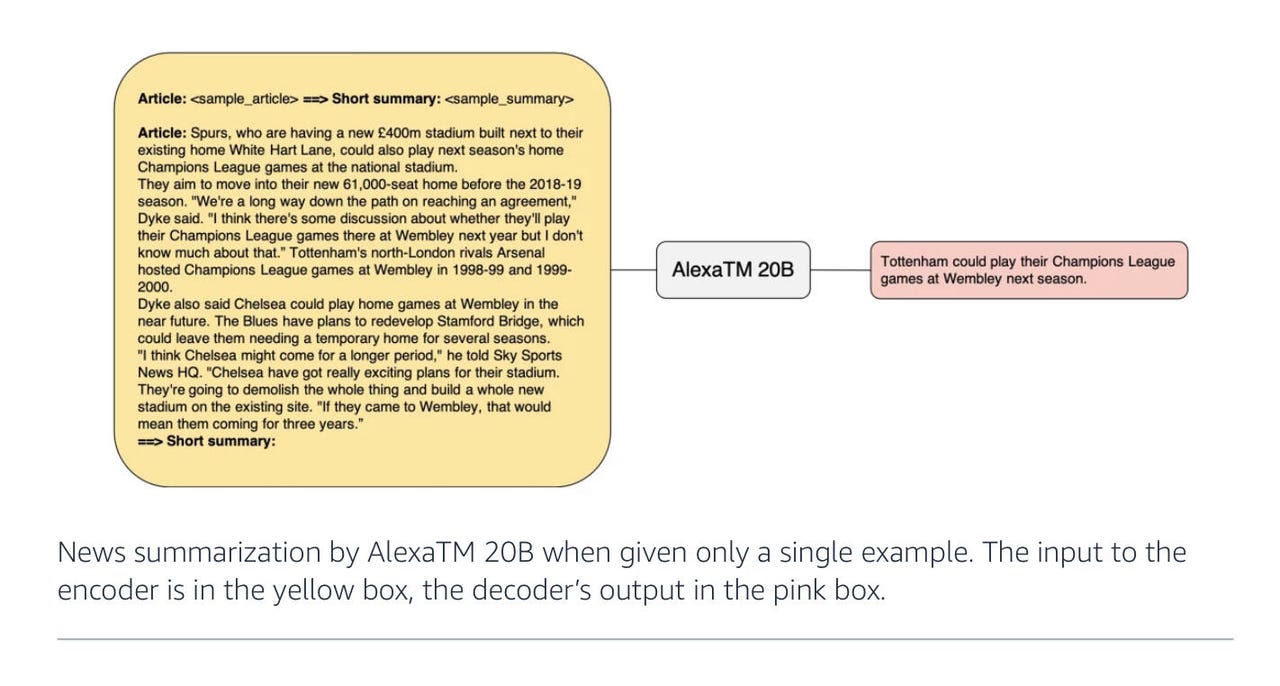
Простая задача по сокращению всех слов в статье до компактной последовательности слов, объясняющей центральную идею статьи, является одной из эталонных задач в области глубокого обучения. Именно здесь ученые по искусственному интеллекту Alexa от Amazon говорят, что они могут превзойти усилия гораздо более мощных компьютерных программ от DeepMind, Google, Meta, OpenAI и других. Эта работа имеет значение для энергопотребления и эффективности углеродного следа.
На сегодняшний день две основные линии исследований сильно влияют на машинное обучение: сделать программы более общими в своем подходе (для работы с любой потенциальной задачей) и сделать их более мощными.
Самые большие нейронные сети, измеряемые по их параметрам или “весам”, содержат более полутора триллионов весов. Модели, такие как Pathways Language Model от Google или PaLM, и Megatron-Turing NLG 530B от Nvidia и Microsoft, являются одними из самых больших, с 540 миллиардами и 530 миллиардами параметров соответственно. В общем случае, чем больше параметров у программы, тем больше вычислительной мощности требуется для ее обучения и работы в режиме предсказания, то есть для выполнения вывода.
Искусственный интеллект
- 7 продвинутых советов по написанию промптов для ChatGPT, которые вам нужно знать
- 10 лучших плагинов ChatGPT 2023 года (и как извлечь максимум из них)
- Я протестировал много инструментов искусственного интеллекта для работы. Вот мои 5 самых любимых на данный момент
- Человек или бот? Эта игра на основе теста Тьюринга проверит ваши навыки распознавания ИИ
Знатоки искусственного интеллекта настаивают на том, что количество параметров определенно растет и в скором времени достигнет триллиона и даже больше. Число 100 триллионов является своего рода магической целью, так как считается, что это количество синапсов в человеческом мозге, поэтому оно служит неким эталоном.
Также: Nvidia уточняет свое утверждение о масштабе Megatron-Turing
- Истинная цель ИИ может больше не быть интеллектом.
- Иллюзия персоны Вы действительно существуете в социальных сетях?
- Метавселенная – это дилемма прав человека.
В то же время существует стремление создать глубокие нейронные сети, которые были бы максимально общими. В течение большей части истории машинного обучения последние 40 лет программы были специализированы для задач, таких как распознавание изображений или распознавание речи. Это изменилось в последние годы, когда все больше программ предлагают быть универсальными, например, Perceiver AR от DeepMind и Gato от той же компании, которую называют “универсальным агентом”, способным решать множество задач.
Тенденция к обобщению была подкреплена наблюдениями пионеров машинного обучения, таких как Ричард Саттон, который заметил, что “исторически общие модели, которые лучше используют вычислительные возможности, в конечном итоге становятся более эффективными, чем более специализированные подходы, сфокусированные на определенных областях”.
Также: ‘Gato’ от DeepMind – среднего качества, так почему его создали?
Тем не менее, существуют результаты глубокого обучения, которые иногда идут в другую сторону: против гигантских и общих моделей в пользу экономичных и относительно специализированных.
В отличие от этих мега-проектов, исследователи из Amazon на прошлой неделе представили нейронную сеть с всего 20 миллиардами параметров, которая превосходит некоторые из самых больших и наиболее общих моделей на некоторых важных эталонных задачах глубокого обучения, таких как сжатие статьи.
В статье “AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model”, опубликованной на прошлой неделе на arXiv, автор Saleh Soltan и его коллеги из Amazon Alexa AI показывают, что 20 миллиардов параметров достаточно для превосходства более крупных моделей, таких как PaLM, в определенных задачах, например, сжатии статьи в несколько предложений.
В дополнение к статье, Soltan написал пост на блоге по этой теме.
Работа Amazon является частью широкого тренда в недавней литературе по поиску альтернатив увеличению размера. Хорошим примером является статья, опубликованная на прошлой неделе от Meta (владельцы Facebook и Instagram) под названием “Few-shot Learning with Retrieval Augmented Language Models”. В ней описывается языковая модель под названием Atlas, которая содержит всего 11 миллиардов параметров и обучается всего на 64 примерах данных.
Как и AlexaTM 20B, программа Atlas в значительной степени превосходит PaLM, пишут авторы, даже с 64 примерами. Ключом к успеху Atlas является комбинация предварительно обученной языковой модели с возможностью извлечения информации из онлайн-источников, таких как Википедия, словно звонок другу за ответом.
Также: Perceiver AR от DeepMind: шаг к более эффективному использованию ИИ
В случае AlexaTM 20B авторы из Amazon используют три модификации, чтобы достичь своих результатов.
Диаграмма AlexaTM 20B от Amazon 2022
Первое интересное изменение заключается в возвращении к основам и восстановлении того, что было исключено из последних гигантских языковых моделей. Основа AlexaTM 20B такая же, как у PaLM и GPT-3 и других моделей, основанных на кодировщике-декодере Transformer – подход, который был создан в 2017 году учеными из Google, Ашишем Васвани и его коллегами.
Transformer использует так называемые “самовнимание” для определения вероятности того, что каждое слово может быть найдено в контексте других слов. Этот показатель затем используется для заполнения пропусков при предсказании слов для формирования значимых текстовых блоков.
В случае AlexaTM 20B Солтан и его коллеги делают существенное отклонение от PaLM, GPT-3 и других гигантских потомков оригинального Transformer. Эти более новые модели отказались от одной половины Transformer, известной как кодировщик (то, что преобразует входные данные в скрытые состояния, которые затем декодируются в ответ). Вместо этого PaLM и GPT-3 объединяют вход с декодером, чтобы создать упрощенную программу, являющуюся моделью “только декодера”.
Команда Alexa возвращает кодировщик в программу. Они утверждают, что наличие обоих элементов помогает повысить точность в так называемом “шумоподавлении”, что означает восстановление исходного предложения, в котором отсутствуют некоторые слова.
В модели “только декодера” условная вероятность предсказываемого текста работает только в одном направлении: каждый следующий ответ основан только на предыдущем. В полной версии кодировщик-декодер модели, напротив, модель оценивает вероятности в обоих направлениях: что предшествует данному слову и что следует за ним. Это работает лучше в задачах, где необходимо не только генерировать следующий элемент в предложении, но и выполнять такие действия, как слово-в-слово сравнение, например, в задачах перевода с одного языка на другой.
Модели “только декодера” AlexaTM 20B от Amazon 2022
Также: Масштабная многоязычная модель перевода Meta все еще имеет проблемы с греческим, армянским, оромо
Как они пишут, “AlexaTM 20B достигает нового передового уровня в 82,63% в режиме нулевого предварительного обучения в режиме шумоподавления. Основная причина, по которой режим шумоподавления работает лучше для этой задачи, заключается в том, что в режиме шумоподавления вход повторяется в кодировщике и декодере, позволяя модели использовать как кодировщик, так и декодер для поиска наилучшего ответа.”
Второе, что добавляют авторы, – это обучение модели с помощью так называемого “причинного моделирования языка”. CLM, сокращенно, – это задача, которая используется в GPT-3 и других моделях Transformer, работающих только с декодером. Она специально представляет каждое слово как зависимое только от слов, идущих перед ним, – последовательная однонаправленная зависимость, которая обучается генерировать предложения на основе исходного подсказки.
Авторы смешивают задачу шумоподавления с причинной задачей при обучении AlexaTM 20B, причем 80% обучающей активности занимает шумоподавление, а 20% – причинное моделирование.
Преимущество добавления причинного моделирования заключается в том, что, подобно GPT-3, оно помогает в так называемом “обучении в контексте”. Обучение в контексте – это широкий подход, охватывающий модели, способные выполнять обучение с нулевым или ограниченным количеством примеров. Это означает, что программа не имеет специфических для области знаний; вы просто даете ей пример подсказки, и программа делает предсказание, соответствующее типу задаваемого вопроса.
Благодаря такому гибридному режиму обучения, AlexTM 20B не только успешно восстанавливает предложения – задача шумоподавления, но также является “первой многоязычной моделью seq2seq [последовательность к последовательности], способной к обучению в контексте”, пишут авторы. Другими словами, это гибридная программа.
Третья интересная модификация от Солтана и его коллег заключается в значительном увеличении количества точек данных, поступающих в программу во время обучения. Во время обучения в программу было введено один триллион “токенов”, отдельных элементов данных, что в три раза превышает количество, используемое в GPT-3. В этом случае наборы данных для обучения состоят из статей Википедии и также набора данных mC4, представленного в прошлом году Линтингом Шуэ и его коллегами в Google. Он основан на текстах на естественном языке на 101 языке из источников данных Common Crawl, полученных с веб-страниц.
Также: Sentient? Google LaMDA похож на обычного чатбота
Использование большого количества обучающих данных является одним из ключевых элементов работы Alexa. Солтан и его команда решили идти по этому пути, они пишут, основываясь на наблюдении, сделанном Джорданом Хоффманом и его коллегами из OpenAI, опубликованном в статье в прошлом марте “Обучение оптимальным вычислениям больших языковых моделей”.
В этой статье Хоффман и его коллеги пришли к выводу, что “текущие большие языковые модели значительно недообучены, что является следствием недавнего фокуса на масштабировании языковых моделей при постоянном количестве обучающих данных”. Исследуя широкий спектр языковых моделей разных размеров и тестируя их с различным количеством входных токенов, авторы пришли к выводу, что “для оптимального обучения вычислительным мощностям размер модели и количество обучающих токенов должны масштабироваться одинаково”.
Таким образом, AlexaTM 20B не только экономична – она стремится доказать, что меньшее количество параметров можно сбалансировать с большим количеством обучающих данных, чтобы достичь убедительной производительности.
ENBLE Рекомендует
Какой Amazon Echo купить? Как выбрать лучшее устройство Alexa для ваших нужд
У Amazon теперь есть целая армия устройств Echo. Некоторые слушают вас. Некоторые также вас наблюдают. Какой вы должны выбрать? Мы поможем вам решить.
Кстати, авторы также стараются сформировать большую часть ввода в виде естественного разговорного текста, убирая заглавные буквы и пунктуацию, что имеет значение в настройках Alexa. “Мы включаем больше устной речи, чем письменного текста, чтобы удовлетворить наши внутренние потребности”, пишут они.
Некоторые технологии команды Alexa AI используются в продуктах Alexa, хотя Amazon сообщил ENBLE по электронной почте, что группа “также занимается исследованиями в будущем”. Модель AlexaTM 20B, сказал Amazon, “в настоящее время является в основном исследовательским проектом”.
Amazon добавил: “Возможно, эта модель будет внедрена в производство в будущем, но только модифицированная версия с ограничениями будет использоваться для разработки функций и продуктов Alexa”.
Также: Масштабная работа Google по машинному переводу выявляет ошибки
Авторы обучают модель AlexaTM 20B “в течение 120 дней на 128 [Nvidia] A100 GPU с общим количеством обновлений 500 тысяч с накопленным размером пакета 2 миллиона токенов (всего 1 триллион обновлений токенов)”, они пишут.
Это может показаться многим, но это меньше, чем PaLM, который Google обучал на двух его TPU-платах четвертого поколения, состоящих из 3072 чипов TPU в каждой плате, которые подключены к 768 хост-компьютерам.
Как отметили авторы Google, Ааканкша Чоудхери и ее команда в апреле, это была “самая большая конфигурация TPU, описанная на сегодняшний день”.
Результаты приведены в конкретных тестовых результатах. Солтан и его команда особое внимание уделяют своему успеху в конкретных задачах, а не во всех возможных задачах. Например, они замечают, что “AlexaTM 20B работает лучше или наравне с самой большой моделью только декодера до настоящего времени (то есть PaLM 540B) в резюмировании как в режиме 1-го шага, так и в режиме донастройки”. Это особенно верно для задачи резюмирования параграфов, известной как MLSum; на немецком, испанском и французском языках AlexaTM 20B победила PaLM уверенно.
Тестовый набор данных MLSum, введенный в 2020 году Национальным центром научных исследований Франции, состоит из 1,5 миллиона статей из газет. Задача заключается в том, чтобы языковая модель выдавала несколько предложений текста, выражающих идею, изложенную во всей статье. Это требует значительного сокращения, очевидно, с сотен слов до десятков.
Amazon
- Как превратить старый планшет Fire в Echo Show
- Обменяйте свои старые устройства на подарочные карты Amazon. Вот как
- Лучшие планшеты Amazon: играй с огнем
- Обзор Amazon Kindle Scribe: спустя 7 месяцев, он почти идеален
На четвертом тесте XSum, проведенном на английском языке, модель AlexaTM 20B оказалась второй, и она обошла версию PaLM, которая была больше, чем AlexaTM 20B, но меньше, чем 540-миллиардная версия PaLM.
Хотя она отлично справляется с резюмированием, модель AlexTM 20B не справляется с некоторыми другими задачами. Например, при тестировании на наборах данных “рассуждение” (таких как MultiArith) и задачах “цепочки мыслей” (которые представляют собой очень простые арифметические задачи, записанные на естественном языке), программа далеко уступает более крупным моделям, таким как GPT-3.
Также: Глава Graphcore утверждает, что будущее искусственного интеллекта – это история программного обеспечения
Команда Солтана пишет: “AlexaTM 20B выполняет задачи немного лучше, чем модели с аналогичным размером, однако мы не наблюдали такого же прироста, как у гораздо больших моделей, например, GPT3 175B, при использовании таких специальных подсказок”, то есть инструкций, предоставляемых программе о следующем шаге в задаче.
“Результаты свидетельствуют о том, что масштабирование параметров модели является важным для успешного выполнения ‘рассуждающих’ задач, как было ранее продемонстрировано […] в моделях только декодера с использованием моделей Instruct-GPT3”.
Сосредоточиваясь на успешных задачах, таких как суммирование, основным выводом, к которому приходят Солтан и его команда, является то, что их смешанный подход к обучению программы – использование как целей удаления шума, так и причинного моделирования языка – является ключом к повышению эффективности.
“Это подразумевает, что смешанное предварительное обучение, а не обязательно дополнительное многозадачное обучение […] является ключом к обучению мощных моделей языка большого масштаба seq2seq (LLM)”, – пишут они.
Возвращаясь к исходному вопросу о размере, как отмечено во многих контекстах, энергопотребление все более крупных программ искусственного интеллекта является этической проблемой в практике искусственного интеллекта. Авторы убедительно доказывают актуальность своего более эффективного подхода.
Также: Этика искусственного интеллекта: польза и риски искусственного интеллекта
Поскольку AlexaTM 20B “гораздо меньше по размеру, чем модели, такие как GPT3 175B, но достигает схожей или лучшей производительности в различных задачах”, они пишут, “постоянное экологическое воздействие использования AlexaTM 20B для вывода значительно ниже, чем у более крупных моделей (примерно в 8,7 раза меньше)”.
Они добавляют: “Таким образом, с течением времени AlexaTM 20B имеет также более низкую углеродную ногу”.
Авторы предлагают таблицу статистики, показывающую относительную углеродную ногу, и здесь есть большая разница в цифрах.
Это сравнительная диаграмма углеродной ноги модели Amazon 2022 AlexTM 20B.
Эта таблица углеродной ноги, возможно, является самым интересным аспектом всего этого. Судя по всему, все большее количество исследований глубокого обучения будет стремиться подвергнуть оценке воздействия на окружающую среду, чтобы показать, насколько энергоэффективным может быть данный подход. Это соответствует всеобщему фокусу на “ESG” – экологические, социальные и управленческие факторы – во всех областях.
Это может означать, что экологическая осознанность в некотором смысле стала частью цели основных исследований в области искусственного интеллекта.
Также: Искусственный интеллект в шестьдесят секунд